提到 “SaaS 出海”这个词大家肯定并不陌生,SaaS 企业将业务拓展到海外市场已经成为许多 SaaS 公司的重要战略方向。随着企业对于灵活性、可扩展性以及成本效益需求的不断增长, SaaS 模式提供了理想的解决方案。对于寻求出海机会的 SaaS 企业来说,全球化市场的巨大潜力尤为吸引人。在许多地区,尤其是发展中市场, SaaS 服务的普及率还远远没有饱和,这也为企业提供了非常广阔的成长空间。
随着全球数字化转型的不断加速, SaaS 服务需求也在持续增长。上周,GTC 2024 全球流量大会在深圳成功召开,Databend 作为新一代云原生数据仓库服务商,也携带领先的出海大数据解决方案亮相本次大会。大会围绕着“角逐技术力,把握 SaaS 出海新姿势”这个话题产生出许多精彩的碰撞火花。Databend 联合创始人吴炳锡出席了本次大会,并带来 《SaaS 出海:Databend Cloud 的定位与实践》分享。Databend 成立至今已有三年,这三年里 Databend 是如何定位产品?怎么做出海?以及如何获取出海用户的?通过以下的分享将为大家一一揭秘。

Databend 创建于 2021 年 3 月,核心团队成员来自 ClickHouse 社区、谷歌 Anthos、阿里云等国内外知名互联网和云计算公司,团队在云原生数据库领域有着丰富的工程经验,研发人员分布在中、美两地,同时也是数据库开源社区活跃贡献者。我们创立的开源云原生数仓项目 Databend,是一个使用 Rust 研发、基于对象存储设计的新一代云原生数据仓库产品,提供极速的弹性扩展能力和按需、按量的 Data Cloud 产品体验,致力于打造开源版的 Snowflake。目前,Databend 在 GitHub 上获得超过 7400 个Star ,拥有 180 多位贡献者,总 PR 数量达到 9700+ ,累计已解决 Issue 接近 4400 个。我们以 Databend 作为内核,打造了商业化产品 Databend 企业版和 Databend Cloud。
目前,Databend Cloud 在 AWS、阿里云、腾讯云、华为云新加坡区都提供了相应的服务。在 AWS 上,我们在美国东一区、西一区以及欧洲区都提供了云服务。未来,我们也会随着用户的需求继续开拓新的可用区。基于我们成熟的部署经验,开一个新区大概只用 2- 3 天,能够极快满足用户的业务需求。
Databend 的适用场景包括实时 OLAP、海量日志/数据归档、财务数据的离线分析等,服务的用户包含多点、微盟、茄子快传、海外的区块链公司,以及南北医药集团、尼泊尔电信、苹果中国、国内汽车厂商等等。
Databend Cloud 产品定位
Databend 团队在数据库领域都工作了十年以上,对数据库行业的痛点非常熟悉。所以当时为 Databend 做产品定位的时候,我们就在想怎么才能帮助企业解决行业里的数据痛点。
出海企业在做海外业务时,很多人都想利用 AWS 稳定的网络和硬础架构去做底层基础设施支撑。看起来一切都是美好的,但随着业务增长,他们不得不面对复杂的产品和架构,数据分析成本越来越高。一方面,可供选择的产品非常多,企业也跟着很迷茫,另一方面,这些产品本身也非常昂贵,除了计算存储费用外,还有网络、备份恢复、跨 VPC 传输等等。
Databend Cloud 的设计目标
Databend 致力于简化这一切,我们的 Databend Cloud 很早就定位在 Snowflake、Redshift、BigQuery 的替换上。用户从这些技术栈迁移到 Databend 上面,基本上 2- 3 周都能完成,而且过程非常顺利。
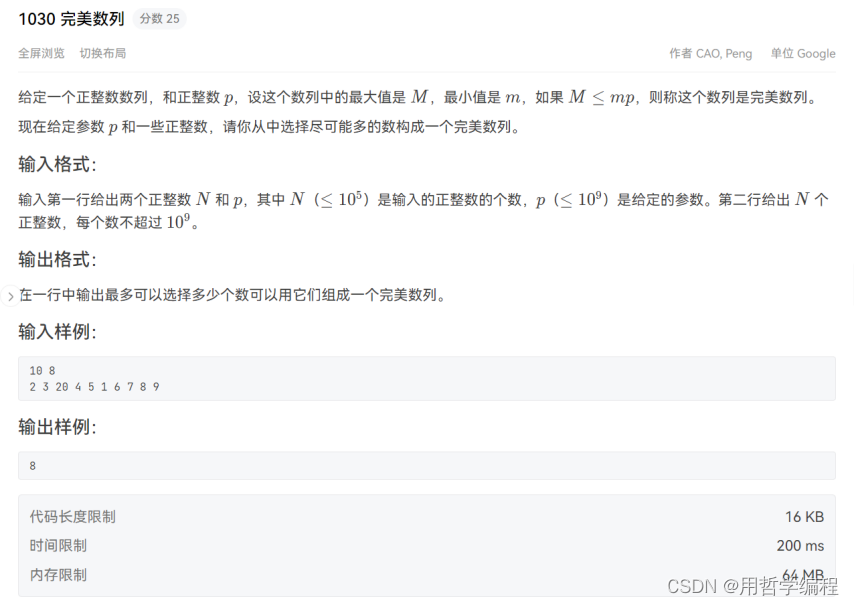
我们为什么能解决这些问题?
首先,Databend 的内核团队非常熟悉 ClickHouse,ClickHouse 在中国 TOP5 的贡献者我们团队占了三个,所以我们基于 ClickHouse 的向量化计算和 Rust 大幅提升了产品性能。同时,我们基于 Snowflake 的存算分离思想,提升了分布式计算能力,借助 Git 实现 MVCC 列式存储引擎,支持事务操作。支持事务也是我们对大数据的一项突破。目前,所有大数据产品其实都不讲究事物,这也造成了金融领域、公司财务报表、公司订单对账经常会丢失数据,或者数据对不齐。我们把数据库的事务理念带到了大数据里面,并用 SQL 的理念解决了这个问题,支持了事务。所以 Databend 在数据对账场景中表现非常完美,支持这个场景完全没有问题。
此外,我们还开源了一个 OpenDAL 项目。2023 年 3 月, OpenDAL 正式移交到 Apache 软件基金会孵化器中进行孵化,将会在今年毕业。它已经成为 Rust 生态以及数据库开发生态里大量使用的组件。
另外,我们把大数据里面大家最痛苦的——任务编排、stream 流计算,还有内部的一些增量获取,全都内置到 Databend Cloud 里,对外提供统一的 SQL 入口。从此,你不用去想什么任务编排了,也不用去搞外置 GPT,只用这一套 SQL 就可以全部搞定。
我们今年刚刚支撑了一个游戏用户,他们原来有一个 30 多人的大数据团队,近半年都在支持一个游戏上线。 据他们介绍,这个游戏上线后需要半年回本,如果回不了本,这个游戏可能就废了。之前,30 多人的团队支撑一个游戏上线其实是很困难的。在使用 Databend Cloud 后,现在一个游戏只需要 2- 3 人就可以支撑住了。
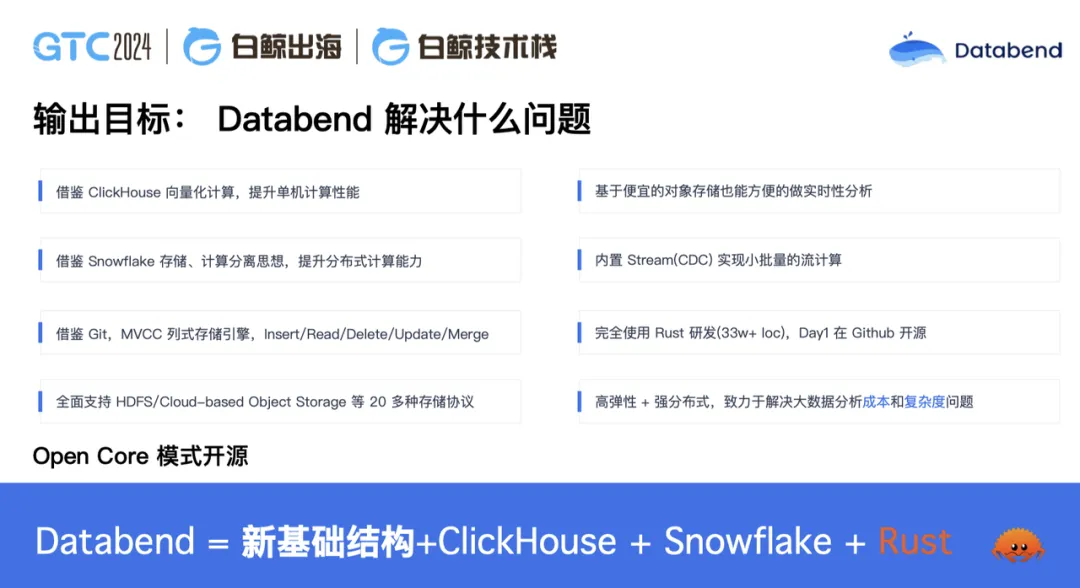
Databend Cloud——基于 Databend 的 SaaS 产品
与其他大数据产品不太一样,Databend 是构建在对象存储之上的一个数据仓库,在对象存储之上你可以用 SQL 去做数据操作。在 Databend 里,你的存储不用搞多副本,不用搞数据分片,也没有分区分表,分库分表,上层就一个表,通过 SQL 来计算就可以了。
这样做的好处是你使用的资源减少了非常多。比如说原来我们做大数据,做数据中转,可能 ClickHouse 要 40 台机器,Kafka 和做数据清洗 ETL 占 100 多台机器,甚至 200 台都可能是正常的。使用 Databend 后,可能就变成了 30 台左右,不用再使用 Kafka 和 ClickHouse。你的数据直接用 S3 接住,然后再往 Databend Cloud 里做数据的清洗、加载、处理,整个过程全是使用 SQL 以及 Python 处理。
我们设计的这个产品,平替了整个大数据技术栈,SQL 使用体验与使用 Snowflake 非常接近。而我们比 Snowflake 更有优势的一点在于我们可以进行私有化部署。如果用户对数据审核要求极为严格的话,甚至还可以把数据放在用户自己的对象存储 Bucket 里面,只把计算放在 Databend。
Databend Cloud 的创新点

Databend 与传统的数仓产品也有非常大的区别。传统数仓基本都会强调分库分表以及分区的概念,它不敢让你把集群扩展得非常大,同时数仓需要保持 always on。数仓产品有个特点,凌晨会做大量数据清洗、报表的工作,所以你会发现凌晨到早上 8 点之间数仓都会非常繁忙。反而到了白天,数仓由于在进行大量的数据加载,并不繁忙。白天它的 CPU 利用率可能只到 5% 左右,非常低。但高的时候 CPU 利用率又会到 100%,又扛不住。
Databend 的做法是,如果说你需要非常大的计算资源,可以让它动态扩展到一个指定的 size。如果你发现实际上并没有那么大的计算需求怎么办?还可以让它动态收缩,甚至收缩到零,这样就没有计算资源,只有存储了。这将为用户实现比较好的成本控制,计算资源是弹性的,存储成本实现本地盘的 1/ 8。
同时,对象存储本身就搞定了副本,所以你也不用搞备份。Databend 的存储引擎从底层设计就支持备份,你所有的操作都可以回滚到上个操作。比如你正在做一个 table,只需一个命令,undo table 就可以回来。再比如 update table,把 table update 错了,可以很方便地回到上一个时间位置。Databend Cloud 在云上默认给用户保留了一天的恢复周期,更长的恢复周期则需要平台恢复。
Databend Cloud 内置了 Task、Stream、insert multi table。其中,insert multi table 是一个非常有意思的功能。在一个征信项目里,数据本身是一个 json 文件,分成了 40 多个 section,是一种半结构化数据,我们的目标是将其清洗成结构化数据去使用。这时候就可以用 insert multi,将每一个部分插到不同的表里面,然后就可以直接使用了。我们可以把一个复杂的 JSON,甚至是不同的 JSON,按不同的位置用 insert multi 插到不同的表里面,这样的话它就变成一种结构化数据去使用。在这个过程里,我们也支持复杂 SQL 的一些大屏,宽表等类型。
另外,我们现在最成功的一点是支持了 Python 的 UDF,我们也支持 Python 的外置 UDF。数据科学家可以用 Python 去写一些数据逻辑,然后用 SQL 来调取。甚至你这个 Python 如果需要 AI 的能力,在特别复杂情况下你可以外挂到外面,直接调机器学习的能力去使用。同时,Databend 提供了 SQL 为统一接口,所有操作都以 SQL 为接口,这让大多数数据开发人员无需再学习就可以掌握。
现在,我们还在实现一个探索功能,在 Databend 内置 CPU 的 AI embedding。如果你的计算过程中没有 GPU 资源的话,通过这个能力可以直接用 CPU 做 AI embedding,会节省大量成本。
帮用户解决问题,Databend Cloud 云上最佳实践
我在创业的这几年里,最大的一个感受是你做的事情别人其实不一定感兴趣。如何让别人对你感兴趣呢?首先你要发现别人的痛点,然后解决了他什么样的问题,在这个问题里面如何辅助他真的能走向成功。
Databend 现在已在游戏、社交、金融、广告、电商等多个行业领域中成功替代 Snowflake、Redshift、BigQuery、GreenPlum、ClickHouse、CDH 等产品,为客户提供了降本增效的大数据解决方案。

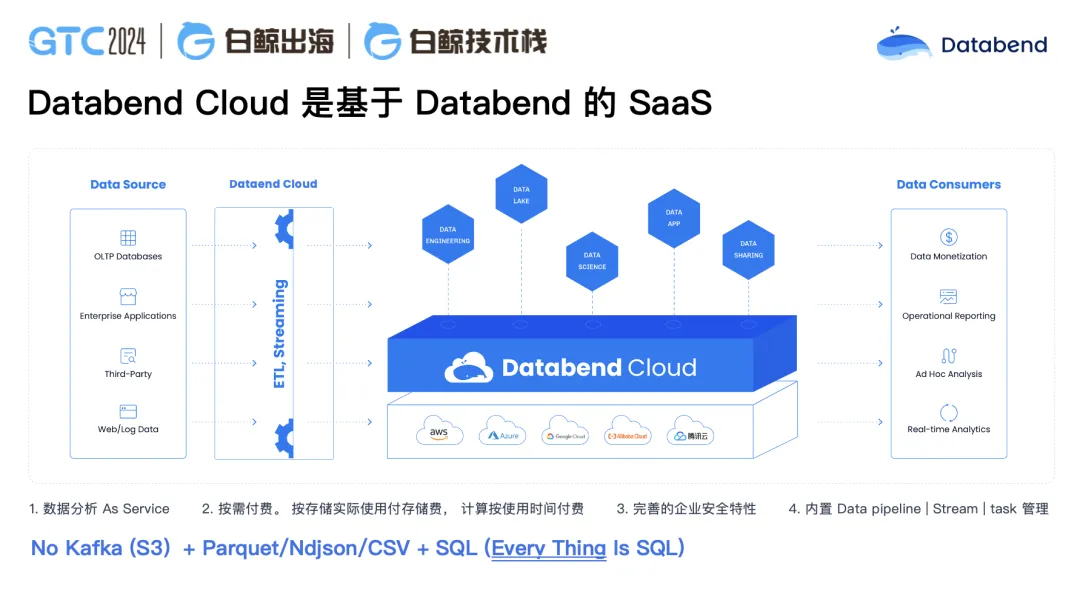
比如上图这个客户是做海外游戏的,大概每秒钟会产生十几万条数据的入库,这些数据再去做分析。原先,从数据到可见都在 Snowflake 上,可以实现分钟级可见。现在迁移到 Databend Cloud 后,它做到了秒级可见,整个数据从可见到使用非常快,同时我们的语法跟 Snowflake 基本一致。数据先写 S3,从 S3 加载到 Databend Cloud 里,做数据的打平,数据的加工,最终对外提供服务。这时候他的数据科学家也可以直接介入进来,进行更多深入的数据分析工作。
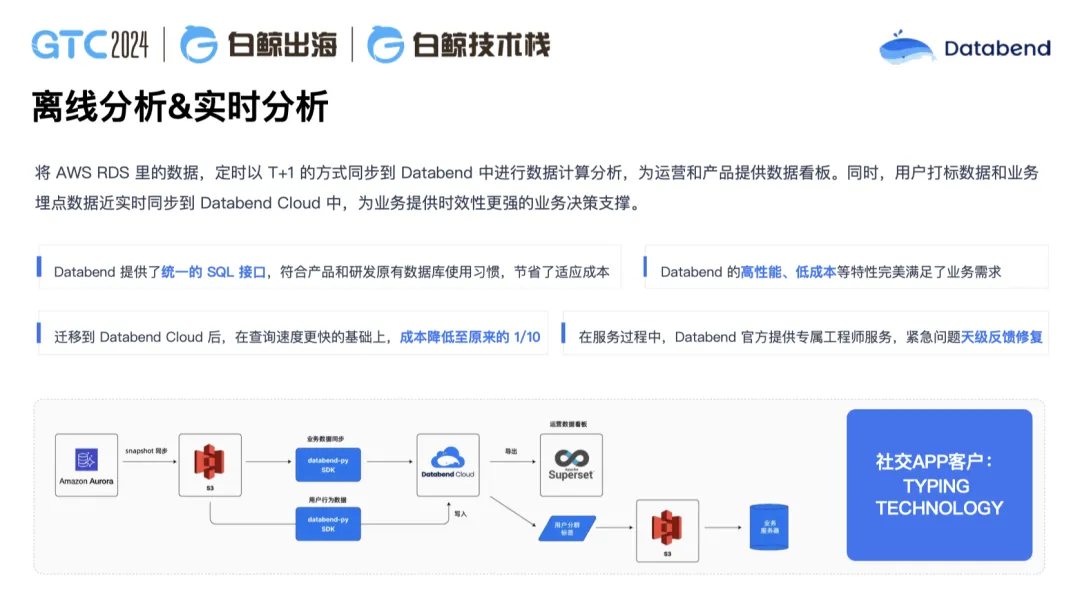
Typing 是我们做过的一个社交用户,原来用的是 Redshift,每个月的消费在 3, 000 美金左右,迁移到 Databend Cloud 后,每个月消费下降到大概 300 美金左右,成本降低了 90%。为什么可以降低这么多?很大的一个原因是他在计算节点不使用情况下,可以直接关闭自动休眠掉,节省了大量的计算资源费用。此外,他的存储从原来的本地盘变成 S3,同时我们在 S3 还引入了压缩,如果你在本地盘的数据是 100G,压完之后就只有 10G。在这个案例中,成本下降非常显著。
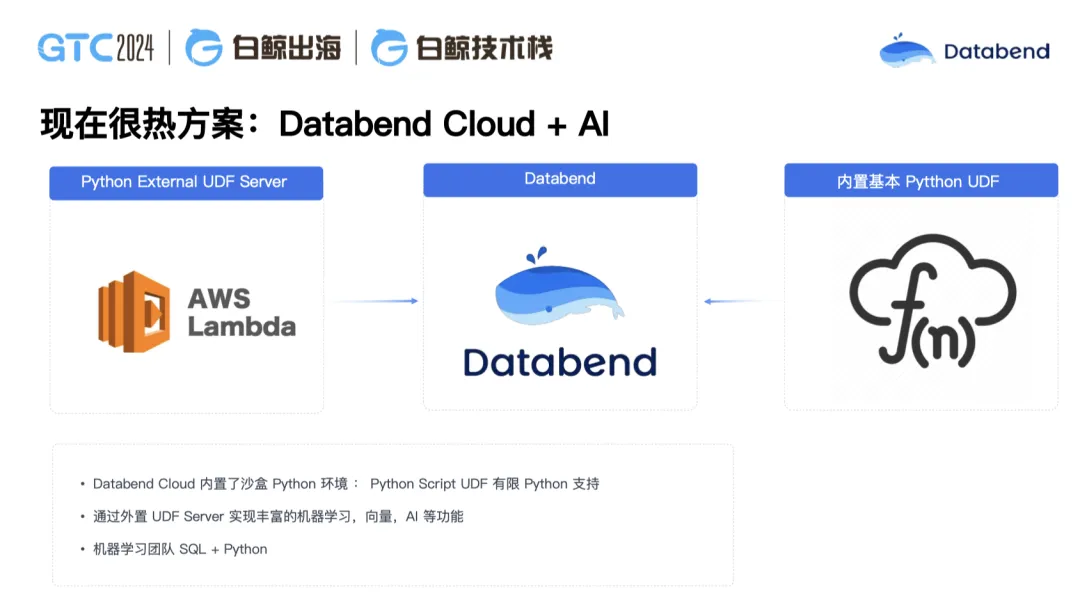
AI 大模型是现在一个非常热的方案,用户也经常问我们如何跟 AI 进行整合。最近,我们在一个医药场景落地了一个应用。当医生在医院里开药,只用把病人的症状输进去,这套方案就会自动把对应的药品说明返还出来。这是怎么做到的呢?首先,我们借助了 AWS Lambda 计算函数,把一些药品的数据进行训练,训练完之后只要输入症状我们就可以把药品对应出来,然后动态选择。这解决了很多医生的烦恼,以前他可能知道这个症状,但不知道还有哪个药能治这个病,我们正在探索的这个 AI+Databend 的方案可以很好地解决这个痛点。此外,我们也正在和金融行业做一些探索,继续拓展更多的落地场景。
在上述场景里,你可以理解为 AI 学习可以借助外部的 Python UDF 去做机器学习训练,训练好的结果集可以供 Databend 使用。在这种情况下,如果说涉及到特别复杂的逻辑,SQL 已经没办法表达了,你就可以用 Python 来定义 UDF 来去使用。我们用 Databend 存储了数据, 使用外部的 GPU 来做向量化计算和机器学习,继续 AI 的一些训练,然后内部整合到 Databend,把数据和机器学习完全打通了。
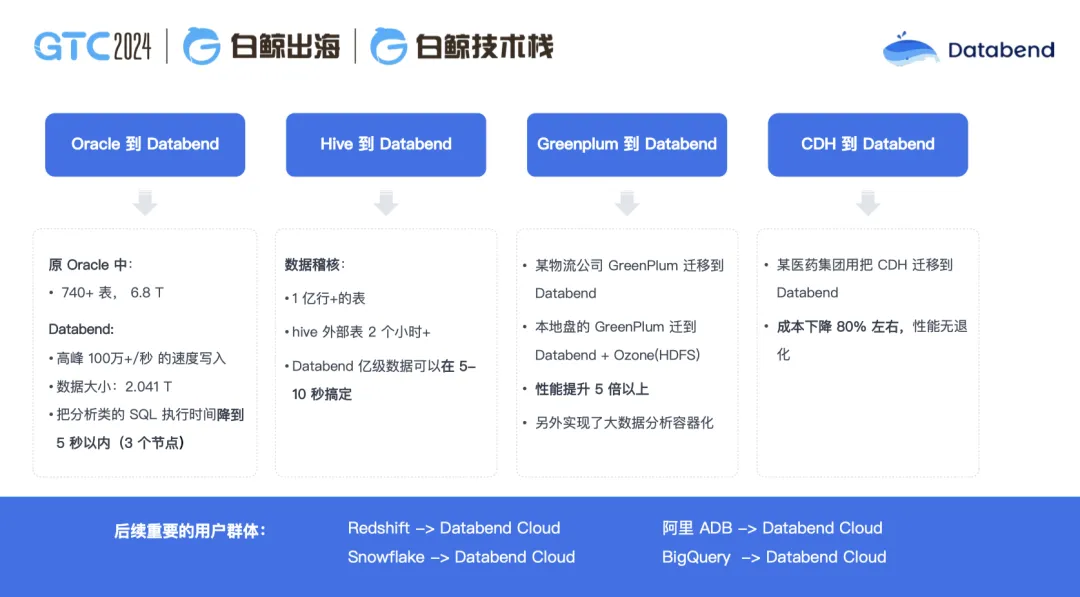
这是我们做的一些案例总结,如果你留意我们社区的话,可能看到过这些分享。比如在 Oracle 的迁移里,原来 700 多张表, 6.8T 的数据,迁移到 Databend 里只有 2T 多的数据,高峰时间达到 100 万+每秒的速度写入,原来一个 80 多秒的 SQL 在 Databend 能稳定跑在 5 秒以内,只要三个节点;从 Hive 到 Databend 的案例,1 亿行+的情况下,做数据比对,在 Hive 里面需要两个小时,在 Databend 里面十几秒就能可以搞定;在 GreenPlum 到 Databend 的迁移场景里,从 HDFS 本地盘迁到 Databend 里,性能得到了 5 倍以上的提升,并且管理更简单,计算也更好扩展;某医药集团把 CDH 迁移到 Databend,成本下降 80% 左右,性能无退化。
今年,我们还在陆续替换阿里 ADB,Redshift,Snowflake,Bigquery 等产品。以前没做大数据前,我其实很少接触到几万亿的表,做了大数据行业之后,我发现万亿级别的表,甚至 PP 级单表都很正常。Databend 集群在万亿级或者 PB 级表的场景下,只需 30 多台机器就可以运行得很好,是应对海量数据分析的完美解决方案。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
Databend Cloud:https://databend.cn
Databend 文档:Databend
Wechat:Databend
GitHub:GitHub - datafuselabs/databend: 𝗗𝗮𝘁𝗮, 𝗔𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝘀 & 𝗔𝗜. Modern alternative to Snowflake. Cost-effective and simple for massive-scale analytics. https://databend.com